Applio使ってみた
ボイスチェンジ技術についに手を出そうと思い、Applioというものを使ってみることにしました。RVCを手軽に使えるようにしてくれています。
https://github.com/IAHispano/Applio?tab=readme-ov-file
ローカルでやりたかったので、WSL2に環境構築しています。単にgit cloneするだけ。run-install.shのようなまとめて依存関係導入するスクリプトも提供されていますが、めちゃくちゃになりそうな予感がしたので、手動で必要なパッケージをインストールして、一通り動作するようになりました。デフォルトのrun-install.shが嫌な理由として、勝手にCUDA12.8のtorchを使おうとするからってのもあります。まともに動く気がしないよ。python -m pip install torch==2.7.0 torchvision torchaudio==2.7.0 --upgrade --index-url https://download.pytorch.org/whl/cu128
私の環境はCUA12.6なので、ここらへんは慎重にいきます。
たくさんエラーは出てきますが、動いているのでヨシ。TensorflowとPyTorchはいつもそう。
python3.12、CUDA12.6環境です。インストールスクリプトはなんかやたらpython3.10を使いたがっていますが、別に3.12でも全く問題なく動作しました。
使用方法について、調べても全然分からなかったので、それっぽいボタンとコードを見比べながら使ってみました。
ステップバイステップでメモするので、未来の自分でも簡単に再現できるでしょう。
念のため、requirements.txtの内容と、動作確認した現環境の比較を載せておきます。
| Package | Required Version | Installed Version |
|---|---|---|
| numpy | 1.26.4 | 1.26.4 |
| requests | >=2.31.0,<2.32.0 | 2.32.3 |
| tqdm | Any | 4.67.1 |
| wget | Any | 3.2 |
| ffmpeg-python | >=0.2.0 | 0.2.0 |
| faiss-cpu | 1.7.3 | 1.11.0 |
| librosa | 0.9.2 | 0.9.2 |
| scipy | 1.11.1 | 1.14.1 |
| soundfile | 0.12.1 | 0.13.1 |
| noisereduce | Any | 3.0.3 |
| pedalboard | Any | 0.9.17 |
| stftpitchshift | Any | 2.0 |
| soxr | Any | 0.5.0.post1 |
| omegaconf | >=2.0.6 | 2.3.0 |
| numba | Any | 0.60.0 |
| torch | 2.7.0 | 2.5.1+cu124 |
| torchaudio | 2.7.0 | 2.5.1+cu124 |
| torchvision | Any | 0.20.1+cu124 |
| torchcrepe | 0.0.23 | 0.0.23 |
| torchfcpe | Any | 0.0.4 |
| einops | Any | 0.8.1 |
| transformers | 4.44.2 | 4.49.0 |
| matplotlib | 3.7.2 | 3.10.0 |
| tensorboard | Any | 2.19.0 |
| gradio | 5.23.1 | 4.24.0 |
| certifi | >=2023.07.22 | 2023.7.22 |
| antlr4-python3-runtime | 4.8 | 4.9.3 |
| tensorboardX | Any | 2.6.2.2 |
| edge-tts | 6.1.9 | 6.1.9 |
| pypresence | Any | 4.3.0 |
| beautifulsoup4 | Any | 4.12.3 |
モデルセッティング
作成するモデルの名前を入力。
サンプリングレートは真ん中の40kに設定。
ここは後程設定するPretrained Modelと合わせる必要がありそうです。

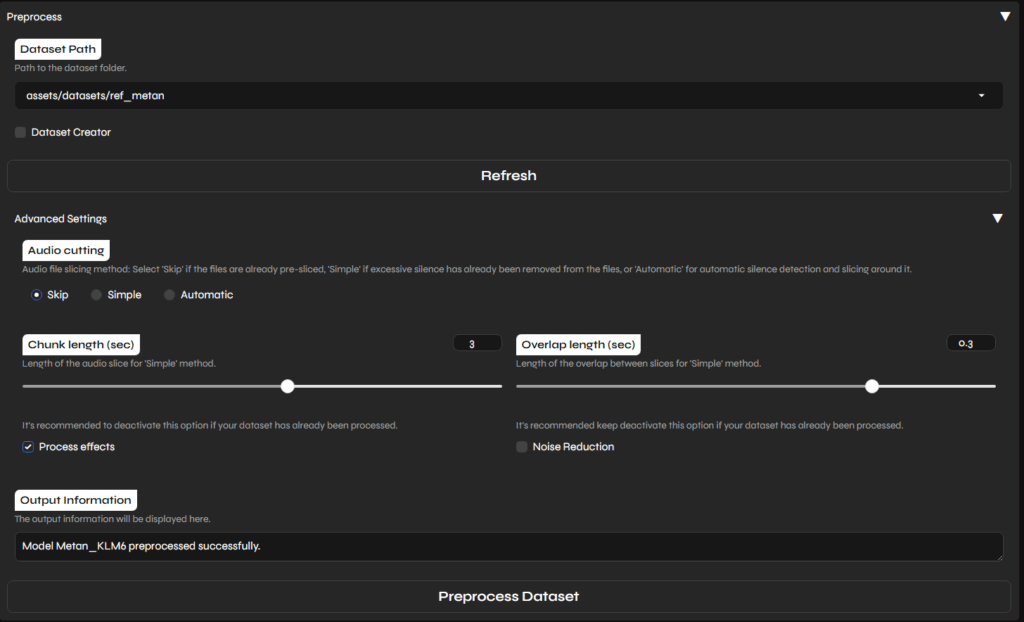
Preprocess
以下のような感じ。Dataset Pathがスキャンしてくれる場所に、めたんさんの音声が300個くらい入ったフォルダをコピー。
私は自前で音声前後の沈黙時間を削除する処理を実施済みでしたが、念のためここでもちゃんと前処理を双方ともオンにしておきました。
メモ: データセット配置
データセットの配置はどこにすればいいのだよ、となったのでコード確認。
# Dataset Creator
datasets_path = os.path.join(now_dir, "assets", "datasets")
if not os.path.exists(datasets_path):
os.makedirs(datasets_path)
datasets_path_relative = os.path.relpath(datasets_path, now_dir)どうやら、assets/dataset/下にある全ファイルが音声拡張子を持つかどうか再帰的に調べて、音声が含まれるフォルダをリストアップしている模様。
ここに、適当な名前でフォルダを切って音声を配置すればいいでしょう。
Pretrainedの結果は?なにをやっているの?
logs/{model_name}以下に、前処理後の音声ファイルやメタ情報が作成されていました。処理後のwavとその16k版とかがまるっとこちらに記録されていそうです。
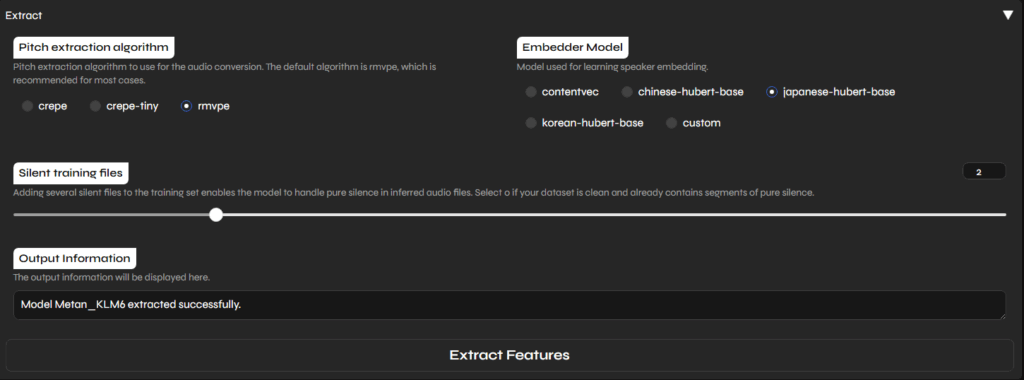
Extract
参照音声からどうにかして何かの特徴量をとってきているんでしょう。
Embeddingは、japanese-hubert-baseだとモデルが滅茶苦茶になってうまくいきませんでした。contentvecのほうが安牌。
出力は?
どうやら全音声について、log以下にf0とかを出力してるらしいです。
トレーニング
まずモデル配置から。
https://huggingface.co/SeoulStreamingStation/KLM6_Experimental/tree/main
ここの、KLM6_Exp2_40khz.pthというのをDとGについて持ってきました。
持ってきたはいいものの配置場所どこだよ、となったので、コード再訪。関連するのは以下部分です。
要は、rvc/models/pretraineds/custom/以下に放り込めば、再帰的に検索してドロップダウンに表示してくれているようです。
# Custom Pretraineds
pretraineds_custom_path = os.path.join(
now_dir, "rvc", "models", "pretraineds", "custom"
)
pretraineds_custom_path_relative = os.path.relpath(pretraineds_custom_path, now_dir)
os.makedirs(pretraineds_custom_path_relative, exist_ok=True)
def get_pretrained_list(suffix):
return [
os.path.join(dirpath, filename)
for dirpath, _, filenames in os.walk(pretraineds_custom_path_relative)
for filename in filenames
if filename.endswith(".pth") and suffix in filename
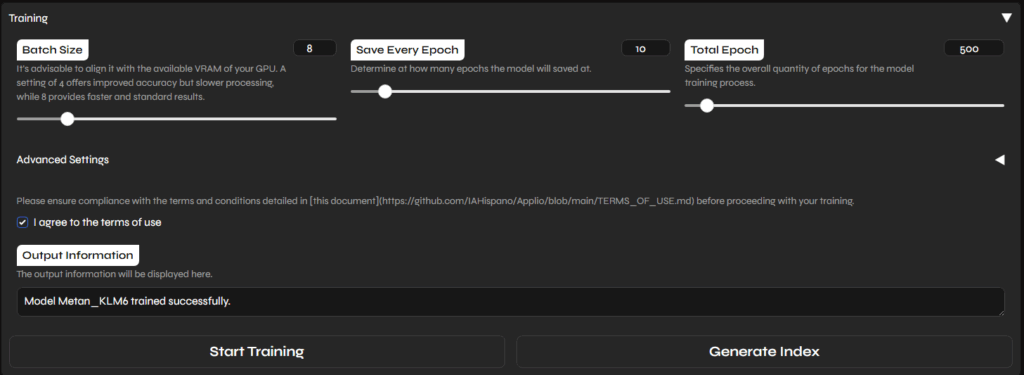
]ここまで来たのでそろそろトレーニングボタンを押せそう。
バッチサイズはGPUの8GB、その他はCustom PretrainedとOvertraining Detectorにチェック。
Index AlgorithmはKMeansにしました。
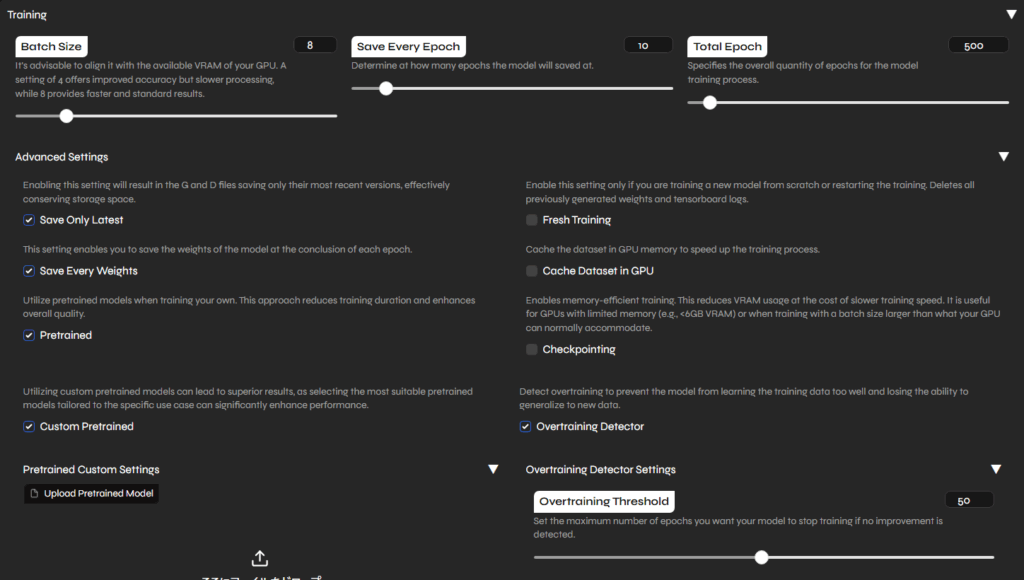
ダウンロードしてきたモデルが選択できるので、そのままボタンをぽちっと。
自分の環境だと、100Epochで40分くらいでした。デフォルトの500Epochで3時間くらい待つ必要がありました。だいぶ長いですね。
出力はlogs/{model_name}/以下に、一定エポックごとに出力されていくようです。
最後の方ではOvertrainingに引っかかりました。オプションをオンにしておいてよかったかも。
ついでにGenerate Indexというのもぽちっと。何かに使えるかも?
実行してファーストトライが失敗した経験から、まず10Epochくらいでやってみて、モデルを使ったボイスチェンジが問題なくいくかいったん確認してからEpoch数を増やした方が時間が節約できます。
同じモデル名でもう一回Epoch数を増やしてTrainingを実行すれば、つづきから読み込んで学習を続けてくれるようです。

補足: matplotlibのエラー発生!
以下のようなエラーが発生。AttributeError: 'FigureCanvasAgg' object has no attribute 'tostring_rgb'. Did you mean: 'tostring_argb'?
だいぶよく見かけるエラーですね。関数を修正して動かしました。matplotlibはいつもこういうエラーを出してきます。
# rvc/train/utils.py Line 167あたりの関数
def plot_spectrogram_to_numpy(spectrogram):
global MATPLOTLIB_FLAG
if not MATPLOTLIB_FLAG:
plt.switch_backend("Agg")
MATPLOTLIB_FLAG = True
fig, ax = plt.subplots(figsize=(10, 2))
im = ax.imshow(spectrogram, aspect="auto", origin="lower", interpolation="none")
plt.colorbar(im, ax=ax)
plt.xlabel("Frames")
plt.ylabel("Channels")
plt.tight_layout()
fig.canvas.draw()
image_rgba = np.array(fig.canvas.buffer_rgba())
image_rgb = image_rgba[:, :, :3]
plt.close(fig)
return image_rgbモデル完成!
二回目のトライで、まともに変換できそうなモデルができました。
試しに変換してみます。以下のサイトの音声サンプルのうち、G-06をお借りします。
https://pro-video.jp/voice/announce/
結果は以下のような音声です。なかなかいい感じです。
ただ、自分の声を録音して変換しようとしてみたら、ものすごく低い声に変換されてしまいました。Formant Shiftingのオプションを付けても、少しマシになりますが聞けたものではありません。事前にピッチだとかでもう少し変換先の音声に近づけておく必要があるかもしれないですね。
かなり明確に、元音声ごとに変換後の感じが変わってきそうに思うので、ここのピッチ調整とかは何とかうまくできないか考えたいところです。めたんさんの音声のピッチに強制的に合わせるように出力音声をシフトさせたりすれば、多少まともになるのかな。
ここからの予定
ここからやりたいことの一つは、いい感じにモデルをミックスして自分好みの音声を作り出すことです。
まあ、それは今回の本題からは外れるので、またの機会に、ということで。
ではでは。

コメント