YMM4
先日合成音声を初めて触ってみたのをきっかけに、簡単に字幕も作れるゆっくりムービーメーカーを触ってみています。(別にどういう動画を作りたいかというイメージはないんですが・・・)
通常のボイスロイドなら何も工夫せずとも動きますが、例えばpythonでTTSとかを活用して合成音声を作っている場合にも、
- セリフをタイムラインの下のところに入力
- pythonを叩いて音声を入力
- キャラクターの音声監視対象フォルダに音声を自動的に出力
- セリフに対応した音声が読み込まれる!
という形で手軽に動かせないか、ということを考えました。
結論から言うと、実現できました。今回は簡単に、どう構成したかを紹介したいと思います。
もしかしたら、今後動画にして初投稿するかもしれません。
前提条件
まず、今回の合成音声は、GPT-SoVITSを用いて合成音声を作成しています。これはpythonで動作しており、後程紹介するようにWeb UI上で音声が生成できるツールとして提供されています。Web UIにテキストとか入力すると、GPUも用いてテキストからwavを出力するのですが、既存のgitレポジトリではこれはwebuiとして動作しており、実行ファイルとして直接叩くのは少し面倒です。また、TTSの場合はモデルをGPUにロードしている必要があるということもあり、毎回exeを実行するのはロード時間がかかりすぎて実用上無理でしょう。
そこで今回は、GPT-SoVITSがgradioというWebアプリ作成のためのライブラリを使用しており、APIが生やしやすいことから、
- GPT-SoVITSのWeb UIを立ち上げるついでに、音声を生成するAPIを生やす
- バックグラウンドで起動させているWeb UIに生やしたAPIを叩くexeを作る
- YMM4において、キャラクター設定の音質を「コマンドライン/コマンドライン/日本語」に設定し、実行ファイルに前述のAPIを叩くexeを指定する
という迂遠な手法を取ることにしました。
このYMM4がexeを叩くときのexeの引数ですが、どうやら第一引数に生成する音声のテキストが指定されて渡されるようです(辞書により変換済みのもの)。
二番目は、C:\Users\xxx\AppData\Local\Temp\YukkuriMovieMaker\v4\xxxx\yyyy.pv4.tmpような、よく分からない仮パスのようですが、今回は使用する必要がありませんでした。
Step 1: GPT-SoVITSでAPIを立てる
まずはここから始まります。python GPT_SoVITS/inference_webui.pyみたいな感じで、簡単にWeb UIを開けるようにカスタマイズしています。
現在の散々デバッグと機能の追加をしたWeb UIは以下のようになっています。泡を吹いてしまいそうな汚さですが、これがhttp://localhost:9872/で立ち上がるようになっています。
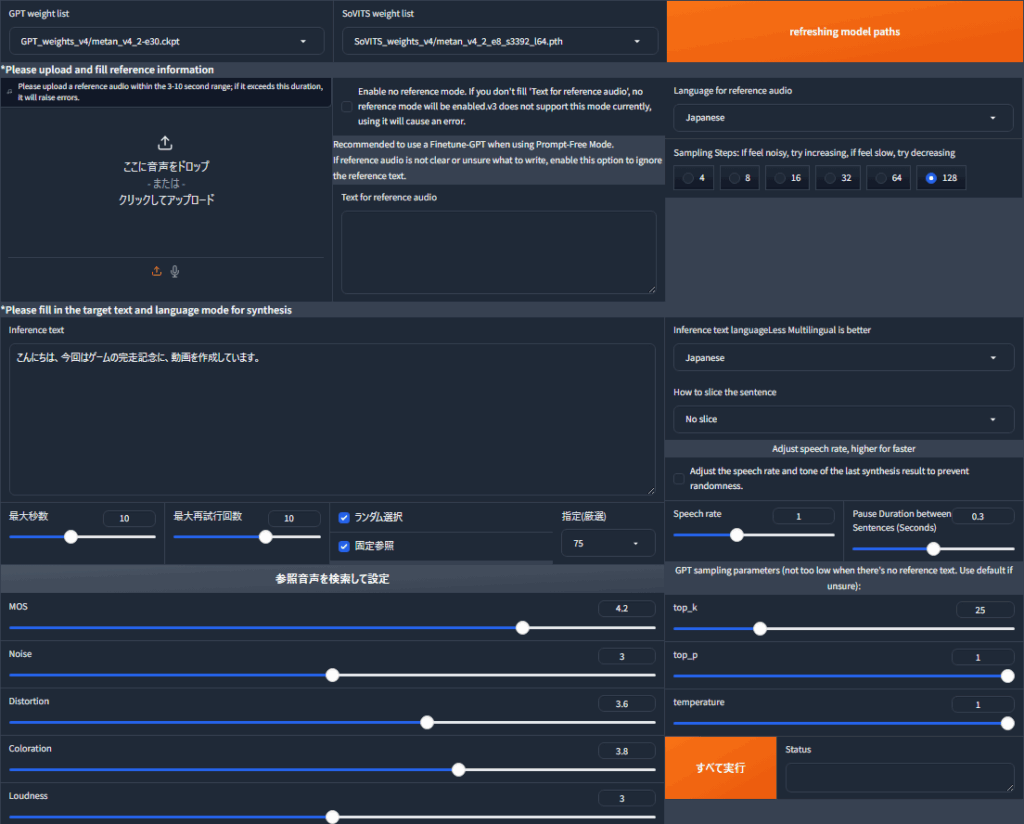
ここで、左下の「すべて実行」というボタンは本当に全てを実行する関数を紐づけていて、
- 参照音声をローカルファイルから勝手に設定
- 音声の推論・生成と後処理
- 指定場所に保存
という処理を全部実行するものです。なお、今回はYMM4との連携を考え、音声出力先はYMM4の監視先フォルダに固定したうえ、生成した音声のファイル名と同名のtxtファイルを作成し、読み上げのトランスクリプトを書き込んでいます。
本質的な引数はInference対象のTextだけなので、この関数に対しAPIを立てればよさそうです。以下のようにしました。
run_all_button.click(
fn=run_all_steps,
inputs=[
... # 引数50個くらい
],
outputs=[run_all_status_text],
api_name="submit_inference",
)api_nameのところに文字列指定してあげれば、その関数がAPIとして外から叩けるようになります。
今回の場合だと、http://localhost:9872/?view=apiというアドレスで、Gradioが立てたAPIを見に行くことができるので、そこでAPIが生やせているか確認できます。
ただ、ここで躓いたのが、なぜかcurlでの叩き方が出てこないこと。exeから叩くにあたり、curlで直接叩きたかったのですが、上のview=apiで表示されるのがpythonとjavascriptでの叩き方のみで、curlについての情報がリファレンスに表示されてくれません。Gradioのバージョンも新しいのに・・・
試行錯誤の結果、今回の場合はhttp://localhost:9872/call/submit_inferenceというアドレスでAPIを叩けることが分かったので、これを使います。以下のようなスクリプトを実行すれば、音声の出力まで行う関数が動作するわけです。なお、このスクリプトはps1です。
# POSTリクエスト送信
$response = Invoke-RestMethod -Uri "http://localhost:9872/call/submit_inference" `
-Method Post `
-Headers @{ "Content-Type" = "application/json" } `
-Body ([System.Text.Encoding]::UTF8.GetBytes($jsonBody))最後のUTF8変換のところは、ps1スクリプト自体がUTF-8 BOM形式とかShift-jisでないと文字化けしそうなこと、そうするとcurlでの送信時に逆に文字化けしてしまうことを原因とした苦肉の策です。
ps1スクリプト自体はUTF-8 BOMで書き、送信時にUTF-8に変換すれば、一通りうまくいきました。
なお、モデルは四国めたんさんの音声で学習しました。めたんTTSです。
https://zunko.jp/multimodal_dev/twdashbord.php
ここのうち、「四国めたん ノーマル 朗読324」の音声素材を加工したのち、GPT-SoVITSのv4をベースとしてファインチューニングしたうえで、自然に聞こえるようにいろいろ頑張って音声加工してみています。
ここの部分もけっこう大変かつ個人的には頑張ったところではあるのですが、機会があれば別の記事ということで・・・
四国めたんTTS サンプル音声:
Step 2: GPT-SoVITSのAPIを叩くexeを作る
今回は、powershellスクリプトをexe化することで実現することにしました。pythonをexe化すると起動に時間がかかる印象があるのと、ps1→exeの変換がかなり楽そうだったのが理由です。
まず、powershellスクリプト本体です。これは、引数を二つ受け取って、一つ目の引数をAPIに渡してやればいいわけですね。ただ、Gradioの設計の関係上、今回はAPIのbodyの中に、先ほど紹介した、APIを叩いたときに動くrun_all_stepsの引数をすべて渡す必要がありそうです(私にはほかの方法が思いつきませんでした・・・)。今回この関数は50個ほどの引数を取っていたので、それはもう汚いことになってしまいました。
# tts.ps1
Param($Arg1_text, $Arg_file)
# JSONリクエストボディを作成(Gradio UIのデフォルト値を使用)
$jsonBody = @{
data = @(
$Arg1_text,
... # 引数他50個くらいハードコード
)
} | ConvertTo-Json -Compress
# POSTリクエスト送信
$response = Invoke-RestMethod -Uri "http://localhost:9872/call/submit_inference" `
-Method Post `
-Headers @{ "Content-Type" = "application/json" } `
-Body ([System.Text.Encoding]::UTF8.GetBytes($jsonBody))
# 結果出力 (不要)
$response | ConvertTo-Json -Depth 3 # 結果をJSONとして整形して出力まあこのスクリプトについてはそこまで言うことはないですね。これをexe化しました。ps2exeというものを使用したところ一瞬で変換完了。
PS XXX> Install-Module -Name ps2exe -Scope CurrentUser -Force
PS XXX> Set-ExecutionPolicy -Scope Process -ExecutionPolicy Bypass
PS XXX> Invoke-ps2exe .\tts.ps1 .\tts.exeみたいな感じで、ps2exeの導入から変換までしていたと思います。
これで、引数一つ目のテキストを用いてGPT-SoVITSの音声合成をトリガーするexeができました。tts.exe "テスト音声" "dummy"みたいにexeを叩けば、inference_webuiで待ち受けているAPIが起動しているはずです。
ちなみに、自分の環境では生成したexeの初回実行時には、毎回Nortonが起動します。ありがた迷惑ですね。
Step 3: YMM4からexeを叩くよう設定する
ここまで来たら安心です。設定はYMM4のGUIで完結します。
YMM4で新しいキャラクターを設定し、以下のように声質のドロップダウンを「コマンドライン/コマンドライン/日本語」に設定、実行ファイルに先ほど作成した実行ファイルを選択します。
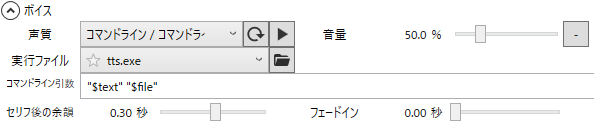
こうすれば、tts.exe "text" "path"みたいな感じで実行してくれます。するとAPIが叩かれて、監視先フォルダに音声が吐き出されて、トランスクリプトも参照してタイムラインに音声オブジェクトが追加されるわけです。
正直、最後動くまでYMM4のここの仕様がどうなっているか、本当に動くのか全く確信がなかったので、動いてよかったと思います。結果オーライ。
動作例
試しにYMM4で、セリフ入力してから音声が生成され、タイムラインに追加されるまでを撮影してみました。だいたい1セリフにつき10秒くらいかかっていますね。Web UI直接叩いた場合はもう少し早いと思います。
また、私はNISQAというもので生成音声のクオリティを測定して、一定のクオリティのものができるまで出力を再生成するような仕組みを導入しています。再生成してクオリティが高い合成音声が得られるまでリトライするオプションをオンにするともっと時間はかかるようになってしまいます。一長一短ですが、自己満足度は高くなります。
まとめ
やればできるものですね。GradioもYMM4も動画編集も、もっと言えばTTSも今回の一連のトライで初めて触ってみているのですが、なかなか思った通りのものが出来上がり満足です。
一つ大きな問題点があるとすれば、GPT-SoVITSの動作環境の整備が面倒ということですね。なにやら公式でDockerイメージを配布しているようですが、それが正常に動作していないといううわさも聞きます。私はもうWSL2上にGPT-SoVITS関連が正常に動く環境の構築を済ませていたのですんなりと行きましたが、まあGitlabとかで今回私が動かしているようなものを配布したとしても、全部すんなり動かせる人は少ないでしょう。
あと、GPT-SoVITSのv4を使えるように私の方で元のレポジトリのコードをいじっており、v4のものを基に四国めたんさんの声で学習をしているのですが、結構性能が上がっているように感じます。コードの修正とかモデルの配置・リネームが面倒だったのが難点です。
ただ、TTSが動画において必要かといわれると少し難しいとも感じました。NISQAやらの音声評価手法を導入して、一定の閾値以上のスコアが出るまで再生成とかすると、だいたい最大5回くらいで十分なクオリティのものが出来上がる感覚ではあるのですが、それも一部イントネーションがおかしいことがたまにある+イントネーションとかアクセントの簡単な修正方法があまりなさそうというのが、少し難儀な点です。Praatという音声編集ツールとか試したんですが、全然簡単に修正できるものではなかったですしね。Googleさんとか、いい感じのベースモデルを公開してくれると嬉しいですね。

コメント