はじめに
試してみました。当方環境ではpytorchもCUDAも何もかも推奨バージョンとは違うので、まあ動かなそうだなと思いつつもやってみました。モノとしてはだいたいGPT-SoVITSをそのまま使っていているようですね。
WSL環境です。
結論から
めでたく動きました。
torchなどはrequirements.txtのものでなく元々入れていたものを使っています。
| OS | Ubuntu 22.04.5 LTS |
| Python version | Python 3.12.8 |
| Torch Version | 2.5.1+cu124 |
| CUDA Version | 12.4 |
| NVCC | release 12.4, V12.4.99 |
インストール
公式にだいたい書いてあります。優しい。
https://github.com/zunzun999/zundamon-speech-webui?tab=readme-ov-file
一応フォルダ構造だけ。
├── GPT-SoVITS
│ ├── GPT_SoVITS
│ │ ├── inference_webui.py
│ │ ├── pretrained_models
│ │ │ └── chinese-hubert-base
│ │ ├── text
│ │ ├── G2PWModel
│ │ └── g2pW.onnx
│ ├── GPT_weights_v2
│ │ └── zudamon_style_1-e15.ckpt
│ ├── SoVITS_weights_v2
│ │ └── zudamon_style_1_e8_s96.pth
│ └── zundamon_webui.py
├── reference
│ └── reference.wav
└── zundamon_speech_run.py感想と雑記
referenceの音声と書き起こしを入力して、Targetのテキストを生成してみました。結構いい感じですが、起伏がオーバーになることが多いのが少し気になりました。
ここからは結構な割合で、ずんだもんとは関係がないGPT-SoVITSの方の話を含みます。
ファインチューニングされたモデルは影響あるの?
今回このWebUiでは、デフォルトだとずんだもんにファインチューニングされたモデルが読み込まれるようweight fileに設定されています。
このモデルの違いがどのくらい出力に影響を与えるのか知りたいと思い、使用するモデルのウェイトを選択できるトグルスイッチを追加しました。
で、モデル変更してみた感想なんですが、ずんだもん用モデルでないものだと、少しだけ似た声ではしゃべってくれていました。思ったよりファインチューニングの影響あるんですかね。
サンプル音声の時間
3~10秒という制限がコード内にあるので、コメントアウトしたうえで少し長めの音声ファイルなど入れてみていますが、生成される音声がノイズだらけになって失敗することも多い印象。
BERTとかと組み合わせるなら、短い音声とその書き起こしを複数セットで与えた方がいいのかも。
パラメータ
Top_K=20、Top_P=1、Temperature=1がデフォなのでパラメータ設定追加して遊んでみました。
適用順はTop_P→Temperature補正→Top_Kの順。
リファレンス音声増やせる?
リファレンス音声はGPT-SoVITSの方の現状の実装だと一つのみ。
せっかくなので複数のリファレンスを活用しようと思ってコード改修してみましたが・・・
- Wav2Vecで特徴量を作ってそれをssl_model(今回だとデフォではcnHuBERT)に渡してVector Quantizationの方に入れているわけなんですが、ssl_modelの出力のshapeが入力ファイルの長さによってたぶん可変で、それに伴いvq_modelの方の出力まで可変になっています。このvq_modelの出力がpromptとしてt2s_modelとして渡されていて重要な役割を担っているわけなのですが、複数音声を活用しようと思った際にどう統合するべきかが分からない。単純に繋げた音声をssl_modelとvq_modelにぶち込むくらいしか思いつきませんでした。サイズが同じなら何か重みつき平均とかあったのかも。
t2s_model.model.infer_panelにおいて、分かりづらい動作をしていて、返り値のpred_semanticとidxのうち、idxがおそらく新規にt2s_modelが生成したトークンの量を表すと思っています。つまり、引数の音素にはreference+target両方を渡していて、一方promptにはreferenceの方のみが入っているので、モデル的にはこのpromptに続ける形でtargetの音素分の特徴量を生成しているのかな。返り値としてはreference+target両方の特徴量が含まれているので、新規生成分を末尾からとってやれば、うまくtarget text分の特徴量が取得できているわけです。
ここの入力に各文章の音素とそのBERT特徴量を渡しているので、複数の音声を使うのなら、個々のリファレンステキストに対して音素取得して、それをつなげてやればいいですね。
といろいろ考えてはみたのですが、そもそもOne-shotでいい性能が出るようなモデルでshotを増やすことにどれくらい意義があるのかそもそもわかりませんね。
日本語だとBERTは動いて無い
T2Sモデルの入力のBertが全部0になっている気がしました。と思ってコードを見たんですが、どうやらデフォルトだと中国語+英語セットの場合にしか対応していないようですね。
"Chinese-English Mixed": "zh"
def get_bert_inf(phones, word2ph, norm_text, language):
language = language.replace("all_", "")
if language == "zh":
bert = get_bert_feature(norm_text, word2ph).to(device) # .to(dtype)
else:
bert = torch.zeros(
(1024, len(phones)),
dtype=torch.float16 if is_half == True else torch.float32,
).to(device)
return bertせっかくなので、モデルどこかからか取ってきて入れてみます。
Ja:bert-base-japanese
Ja+En:bert-base-multilingual-cased
いろいろコードを改修してBERT取り込めないか試していたのですが、これが大変な主な理由は、「音素」と、「各音素に対応する特徴量」の紐づけが難しいから、ということに思えます。
中国語の方での動作を見ると、BERTでTokenizeしてそれぞれについてBERTが特徴量を出力しているわけですが、そのTokenが何音素分に相当するかが割と簡単に取得できているみたいです。それが分かっていさえすれば、各音素についてどのTokenのBERT出力を適用すればいいかもすぐに分かります。今の実装としては、各トークンに対応する音素に、一様に対応するトークンについてのBERTを当てはめています。そうすることで、全音素にBERT特徴量を割り当てることができているわけですね。
さて、日本語でこれが簡単にできるかという話ですが、日本語のBERTではTokenizeしたときに、単語がサブワード?まで分割されているようです。'こん', '##にち', '##は'、みたいな感じですね。で、そうすると、これらサブワードまで分割されたそれぞれのTokenが、どの音素に対応するのかはそこまで自明ではないわけです。
自明ではない理由としては、全文をopenjtalkとかで音素にするときと、サブワード、もしくは単語単位で音素にするときで出力が異なってくるから。
つまり、音声生成の際に出力する音素は当然全文について解釈する必要があるのですが、その全文について計算した音素はサブワードTokenについての音素と一致する保証はないわけですね。
まあ、こんなことがありまして多少難しい点はあるのですが、自分的にある程度納得できるアルゴリズムは作成することができたので、今回はそれを用いてBERT特徴量を日本語読み上げに含めてみています。
スピード調整がしたい!
以下のところでスピードが調整できるようです。
スライドバーをUIに追加して、スピード変更できるようにしてみました。
vq_model.decode(
pred_semantic,
torch.LongTensor(phones2).to(device).unsqueeze(0),
refers,
speed=speed,
)リファレンス音声の取り込み方
デフォのWebUI仕様だと、ファイルをアップロードして、その書き起こしを手入力して、と煩雑なのが気になりました。
ずんだもんなら音声データとその書き起こしはファイルにまとまっているので、参照を番号のリストでできれば便利だと思い、改造してみました。
番号のリストをカンマ区切りで与えれば、自動的に各参照ファイルの音声とテキストを取得するようなものができたので、参照音声を変えて試行したい場合とかはだいぶ便利になるんじゃないでしょうか。
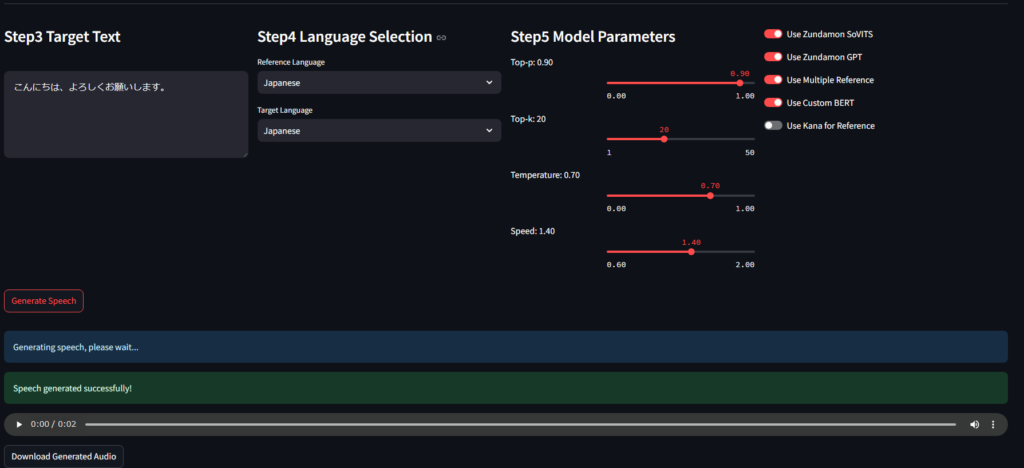
勝手に改造したWebUI
私が考える最強のUIがこれだ!
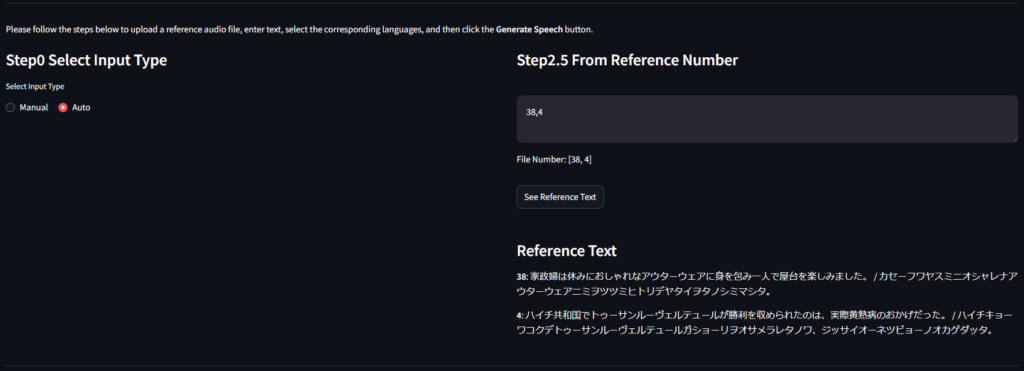
いいところ
- 番号だけで参照音声を入力して事前確認もできる!楽!
- モデルパラメータ設定可能!楽しい!
- いろいろ推論方法をカスタマイズ可能!楽しい!
出力例
色々パラメータ変えて出力を見てみました。全部同じじゃないですか!
最強のずんだもんを選んでください。
| Top P | Top K | Temp | Zunda SoVITS | Zunda GPT | Speed | 音声 |
|---|---|---|---|---|---|---|
| 1.0 | 15 | 1.0 | × | × | 1.0 | |
| 1.0 | 15 | 1.0 | 〇 | × | 1.0 | |
| 1.0 | 15 | 1.0 | × | 〇 | 1.0 | |
| 1.0 | 15 | 1.0 | 〇 | 〇 | 1.0 | |
| 1.0 | 15 | 0.5 | 〇 | 〇 | 1.0 | |
| 0.7 | 10 | 0.3 | 〇 | 〇 | 1.0 | |
| 1.0 | 15 | 1.0 | 〇 | 〇 | 0.6 | |
| 1.0 | 15 | 1.0 | 〇 | 〇 | 1.6 |

コメント